- Salice Thomas
- Follow Me
- November 8, 2025
-
RAG (Retrieval-Augmented Generation) is an AI framework that enhances the accuracy and reliability of a large language model (LLM) by first retrieving relevant information from a knowledge base and then using that information to inform its response. It’s an architecture designed to make large language models (LLMs) like GPT more accurate and up-to-date in real information.
It solves one of the most pressing issues in artificial intelligence which is the problem of factual hallucinations. Instead of relying solely on a large language model’s (LLM) static, pre-trained knowledge, RAG equips it with a “look-up” function. When a query is received, the system first retrieves the most relevant information from a designated knowledge base such as company documents or recent databases. This retrieved context is then fed to the LLM alongside the original question, grounding its response in verified, external evidence. The result is a dramatic increase in answer accuracy, timeliness, and reliability.
Core Components
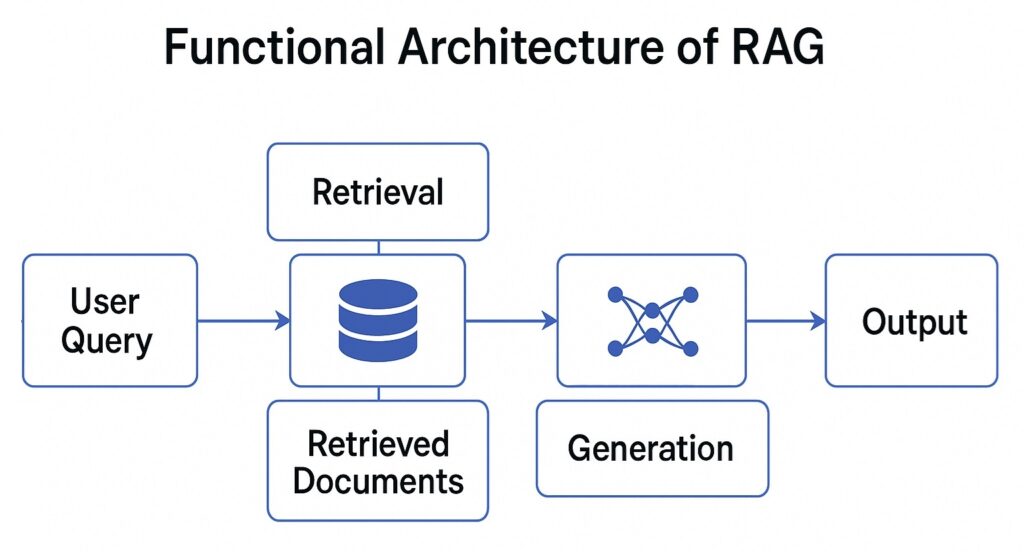
The core components of Retrieval-Augmented Generation (RAG) are the Retriever and the Generator, which work together to combine knowledge retrieval with natural language generation.
Retriever: This is responsible for finding the most relevant pieces of information from an external knowledge base or document repository. Instead of relying solely on what the model learned during training, the retriever searches through sources such as PDFs, enterprise data, or web articles using semantic similarity. For instance, when asked “How does regenerative braking work in automotive?”, the retriever locates passages explaining concepts like energy recovery and motor torque reversal from technical manuals or knowledge stores. This ensures the system has accurate, domain-specific context before generating an answer.
Generator: usually a large language model (LLM) like GPT-4 or Llama 3, takes both the user’s query and the retrieved information as input to craft a coherent, human-like response. It reads the retrieved text, interprets its meaning, and produces a fluent answer grounded in factual data rather than memory alone. For instance, after receiving technical details from the retriever, the generator might produce: “Regenerative braking converts kinetic energy into electrical energy, improving EV efficiency by 10 to 15%.”
Together, these two components create the RAG pipeline’s strength — the retriever ensures accuracy and relevance, while the generator ensures fluency and comprehension. This combination allows RAG based systems to provide responses that are not only conversationally natural but also factually grounded and dynamically updated.
How RAG Works?
Phase- 1: Building Knowledge Base
This is the crucial setup stage that happens before any questions are asked.
Ingest: The process starts by collecting all the documents you want the system to know about—PDFs, internal wikis, databases, web pages, etc.
Chunk: These documents are too large to be processed efficiently. They are broken down into smaller, manageable “chunks” (e.g., a paragraph, a few sentences). Getting the chunk size right is key for retaining context.
Vectorize & Index: This is the magic step. Each text chunk is passed through an embedding model, which converts the text into a numerical representation called a vector embedding. Think of this as a unique “fingerprint” for the meaning of that text.
These vectors are stored in a special database called a vector database (or index). This database is optimized for one thing: finding similar vectors quickly.
Phase -2: Runtime
Step-1: Retrieve
The user submits a query (e.g., “What is the company’s maternity leave policy?”).
This query is converted into a vector embedding using the same embedding model from the preparation phase. It now exists as a numerical “fingerprint” of the question’s meaning.
The system takes this query vector and performs a similarity search in the vector database. It asks, “Which pre-stored text chunks have vectors most similar to the query vector?”
The top k most relevant chunks (e.g., the top 4-6) are retrieved. These are the most semantically similar pieces of information, likely containing the answer.
Step-2 : Augment
The retrieved text chunks are now combined with the original user query to create a new, super-powered prompt for the Large Language Model (LLM).
The augmented prompt might look something like this:
Step 3: Generate
This enriched prompt is sent to the LLM (like GPT-4 or Llama). The LLM now generates a response. Critically, it is constrained and guided by the provided context. It is no longer relying on its internal, potentially outdated or generic knowledge. It synthesizes the retrieved information into a coherent, natural language answer.
The final output is a well-formed, accurate, and context-specific answer, often with citations to the source chunks.
Future of RAG
The future of RAG in AI is poised to redefine how intelligent systems learn, reason, and communicate. As organizations increasingly demand accurate, explainable, and domain-specific AI, RAG will become the foundation for trustworthy enterprise applications. We are moving towards advanced reasoning engines where RAG will perform multi-step research across diverse data formats including images, audio, and structured databases in a seamless multi-modal fashion. It will evolve into a proactive, self-correcting system that critically evaluates its own sources and iteratively refines its searches to ensure unparalleled accuracy. Most profoundly, RAG will serve as the dynamic long-term memory for AI agents, enabling them to perform complex, real-world tasks by grounding every decision in verified, up-to-date information.


